Integration mit Office-Anwendungen
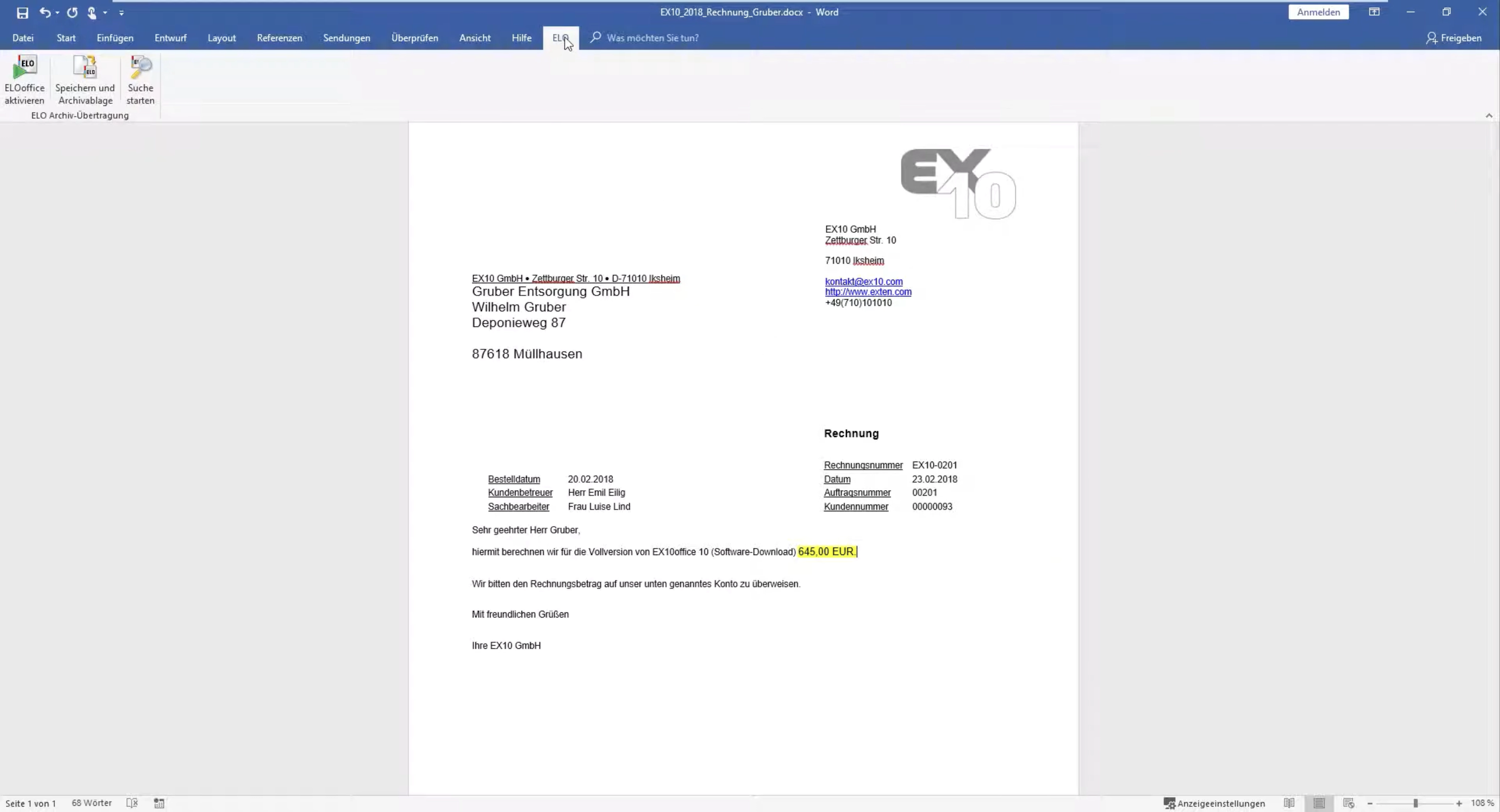
Eigenerstellte und fremderstellte Dokumente
Papierdokumente und elektronische Dokumente
Einmalige Übernahme und laufende Übernahme
Editoren für Texte, Graphiken, Mails, etc.
(Office, Outlook, AutoCAD, ....)
Dokumentenerzeugende Systeme
(z. B. Rechnungen aus ERP-Systemen) (COLD)
Übernahme von Bildern aus speziellen Verfahren wie Röntgen
Herkunft der Dokumente
Posteingang (Papier)
Übersendete Dateien
E-Mail-Eingang
Typische Problemstellungen
Unterschiedliche Formate
Ermittlung und Erfassung der Metadaten
Probleme beim Eingang als Papier
Aufbereitung des Eingangs
Qualitätsunterschiede
Umsetzung in ein CI-Format
Non Coded Information (z. B. Texte in Bildern)
Coded Information
Papierdokument
S/W oder farbig?
Automatisch auszuwerten?
Aufwand für manuelle Vorbereitung (Entheften, Glätten, ..)
Elektronische Dokumente
Welches Dateiformat liegt vor? Konvertieren?
Automatisch auswertbar?
Strukturiertes Dokument oder Fließtext?
Workflow zur strukturierten Abarbeitung
Ausnahmebehandlungen vorsehen
Möglichst automatische Klassifikation und Indizierung
Enterprise Content Management
Quellen
Altsystem (Archiv, DMS)
Filesystem
Mikrofilm, Mikrofiche etc.
Papierbeständen
Zu Klären
Was ist wirklich sinnvoll zu übernehmen?
Automatisierbare Übernahme möglich? (Zeitaufwand!)
Outsourcing prüfen
Eingehende Papierpost
Eingehende E-Mails
Ausgehende Dokumente
Ausgehende E-Mails
Fortschreibungen von Dokumentationen, Akten etc.
Sichere Übernahme des Dokuments in das DMS/Archiv
Protokollieren des Eingangs
Zählen (Scanprozess) und paginieren
Zeitsignatur / Bearbeitersignatur
Klassifikation des Dokuments und Indizierung
Manuell durch Bearbeiter
Automatisch (Formularerkennung, OCR - Volltext, Barcode)
Gemischte Verfahren
Zuordnung zu einem Geschäftsvorfall
Abgeleitet aus Metadaten
Durch Bearbeiter
Weitere Bearbeitung veranlassen
Weiterleitung (E-Mail)
Workflow
Scanner sind die gängigsten Erfassungsgeräte für Dokumente auf Papier oder Film
Scanning ist ein komplexer mehrstufiger Prozess zur Erfassung von Dokumenten
Scanning ist meist mit weiteren Verarbeitungsschritten eng verknüpft.
Zum Scannen und der Folgebearbeitung werden oft Speziallösungen eingesetzt.
Festgelegt wird:
Auflösung
Farbe oder S/W
Trennseiten
Barcodes
Duplex
Zielformat
...
Scanner unterscheiden sich in:
Zufuhr von Seiten
Vorlagengröße (z. B. A4, A3)
Geschwindigkeit (bis zu mehrere hundert Seiten pro Minute)
Farbtiefe
Umschlagerkennung
Heftklammererkennung
Preis
...

Umwandlung von Images (NCI) im CI-Dokumente (wie Texte)
Klassifikation und Indizierung der Dokumente
manuell
automatisch
Automatisches Auslesen von Formulardaten
Automatisches Auslesen von Rechnungen oder ähnlichem
(Z. B. wenn die Dokumentenklasse bekannt ist.)
Primär auf Basis der Form der Zeichen der Maschinenschrift werden Pixelmuster in Zeichen umgesetzt.
Erkennen von handschriftlichen Texten.
Weiterentwicklung von OCR und HCR: Das Ergebnis wird verbessert durch modernste Algorithmen und KI-Verfahren.
Es werden Markierungen in vordefinierten Feldern/Bereichen ausgelesen. Z. B. Selektionsfelder aus Fragebögen oder es wird geprüft, ob „eine Unterschrift“ in dem vorgesehenen Feld erfolgt ist.
Fehleranzahl hängt stark ab von...
Vorlagenqualität (Knicke, Schmutz, ...)
Schriftgröße
Sonderzeichen
Schriftart (mit/ohne Serifen...) und Qualität des Ausdrucks
Qualität der Software
Vorinformationen (welche Schriftarten werden verwendet...)
Problemfälle
Ligaturen (z. B. ffi statt ffi oder fi statt fi)
Bestimmte Zeichenkombinationen z. B. rn: „r“ gefolgt von „n“ oder „m“
Großes I (wie Ida) und kleines l (wie lieb) bei serifenlosen Zeichensätzen
Fremdsprachige Zeichen (z. B. „$“, „¥“ oder „£“)
Optisch beschädigte Zeichen
Es muss unterschieden werden zwischen:
nicht erkannten Zeichen → werden von OCR-Software i. d. R. entsprechend markiert
falsch erkannten Zeichen → müssen im konvertierten Text mühsam gesucht werden
Serifenlose Zeichensätze sind solche, bei denen die Zeichensätze keine Endstriche an Zeichen haben, z. B. Arial, Helvetica oder Noto Sans (dieser Foliensatz verwendet Noto Sans (Display)).
Schriftarten mit Serifen sind z. B. Times New Roman oder Garamond.
Werden zur Identifizierung von Dokumenten eingesetzt.
2 Einsatzgebiete:
Selbst erzeugte Dokumente (z. B. Anträge) mit Barcode-Aufdruck: Beim Rücklauf automatisch erkennbar.
Für Fremddokumente: Barcode-Etiketten (Szenario: „Spätes Archivieren“).
Sehr robust und etabliert.
Bar-/QR-Codes weisen sehr hohe Erkennungsraten auf.
Drei typische Erfassungsszenarien für Eingangspost:
Scannen im Posteingang (frühes Archivieren)
Scannen zum Zeitpunkt der Bearbeitung
Scannen nach der Bearbeitung (spätes Archivieren)
Eingehende Dokumente werden vor der eigentlichen Bearbeitung gescannt
Scannen erfolgt meist im Posteingang
Weiterleitung an Sachbearbeiter auf elektronischem Weg
Vor elektronischer Weiterleitung: evlt. Klassifikation + evtl. Attributierung
Vorteil: Elektronische Weiterleitung
Kurze Transportzeiten, geringe Transportkosten
Weiterleitung an mehrere Personen
Evlt. automatisierte Adressermittlung
Steuerung und Verfolgen der Bearbeitung (Workflow)
Nachteile:
Sachbearbeiter benötigen Arbeitsplatz mit DMS-Zugang
ggf. Neuausrichtung des Geschäftsprozesses
ggf. aufwändiger Einstieg
Dokumente gelangen in Papierform zum Sachbearbeiter.
Dort werden sie direkt vor oder gleich nach der Bearbeitung eingescannt, attributiert und abgelegt.
Einsatzgebiet
Erfassung, Nachbearbeitung oder Attributierung ist aufwendig oder erfordert spezielle Sachkenntnis
fehlgeleitete Belege werden in das DMS eingebracht
(Ggf. in Ergänzung zum „Frühen Archivieren“.)
kleine Dokumentenmengen, nicht für Massenbearbeitung geeignet
Nachteile
Bearbeitungsplätze müssen mit Scanner ausgestattet sein
ständiger Wechsel zw. Dokumentenerfassung und Bearbeitung stört Arbeitsfluss
Einsatz teurer Personalressourcen (Sachbearbeiter) für einfache Tätigkeiten (Scannen, Attributieren)
Papierdokumente werden nach ihrer Bearbeitung an die zentrale Erfassungsstelle geschickt und dort eingescannt.
Zusätzlich wird ein Identifikator für das Papierdokument benötigt.
für Zuordnung des Papierdokuments zu Vorgang während Bearbeitung
Bar-/QR-Code oder Referenznummer/Belegnummer
Bar-/QR-Code:
Registrierung: Dokument erhält eindeutigen Barcode z. B. im Posteingang oder durch Sachbearbeiter
Barcode-Erfassung mit Barcodestift oder Lesepistole
Erfassung des Papierdokuments
Erfassungssoftware erkennt Code automatisch
Code auf der ersten Seite kann gleichzeitig für Dokumententrennung genutzt werden
Die Zuordnungstabelle zw. Code und Dokument ist regelmäßig zu prüfen, ob alle registrierten Dokumente zwischenzeitlich gescannt wurden
Typischerweise werden die Codes nach Erfassung des Dokuments nicht mehr benötigt und eine Wiederverwendung ist ca. nach einem Jahr möglich.
Vorteile
Arbeits- und Papierflüsse können weitgehend wie bisher abgewickelt werden.
Papierdokumente (z. B. Rechnungen) können vor ihrer Erfassung noch geprüft und abgezeichnet werden: Stempel, Unterschrift, Korrekturen werden beim Scannen erfasst.
Arbeitsplätze der Sachbearbeiter erfordern keine spezielle Ausstattung.
Nachteile
Eigentliches Potenzial elektronischer Dokumente wird nicht genutzt.
Gefahr des Verlusts oder der Beschädigung des Papierdokumentes höher.
Entscheidungsdimensionen:
frühes Scannen vs. spätes Scannen oder Scannen bei der Sachbearbeitung
zentrales Scannen vs. dezentrales Scannen
scannen und indizieren gleichzeitig oder zeitlich versetzt
Selbst scannen oder Outsourcing (externer Dienstleister)
(ursprünglich Computer Output on Laser Disk)
Begriff stammt aus der Zeit Mitte der 80er Jahre, hatte sich aber bereits zu Beginn/Mitte der 90er technologieunabhängig verallgemeinert.
Beschreibt die direkte digitale Speicherung von Druck- und Listenausgaben betrieblicher Softwaresysteme (z. B. direkt von ERP Systemen oder von Office Anwendungen über spezielle Druckertreiber).
Die Recherche kann danach wie bei jedem anderen Dokument im DMS erfolgen.
COLD bei größeren Unternehmen bzw. DMS-Lösungen sehr verbreitet.
COLD-Verarbeitung ist typische Batch-Verarbeitung.
d. h. bei COLD werden die Daten nicht mehr - bzw. nur optional - auf Papier ausgegeben, sondern stattdessen direkt in ein DMS übernommen. Da kein OCR notwendig ist, sondern die Daten direkt „beim Drucken“ abgegriffen werden, ist die Qualität der Daten sehr hoch.
Verarbeitung auf COLD-Server
Zerlegung des Datenstroms in einzelne Dokumente.
Extrahiert die für die Ablage bzw. spätere Recherche der Dokumente notwendigen Index-Daten automatisch + evtl. Bezug zu Overlays.
(Die Fachdaten und das Layout sind getrennt.)
Konvertierung bringt die Dokumente in eine für die Ablage geeignete Form.
Beschreibende Merkmale für Dokumente
Ziel ist das möglichst exakte Wiederfinden der richtigen Dokumente (strukturierte Suche!)
Metadaten sind strukturiert und möglichst exakt vordefiniert (z. B. Wertebereiche)
Quellen für Metadaten:
Manuelles Erfassen
Aus dem Dokument automatisch ermitteln
Aus anderen Anwendungen / Quellen übernehmen
Freitexteingabe (z. B. Zusammenfassung, Notizen)
Unterstützung durch Auswahlmenüs, Formatvorgaben oder Defaultwerte, z.B
Schlagwortindizierung (definierter Wortschatz)
Formalisierte Eingabe (z. B. Datum)
Probleme:
Fehleranfällig
Aufwändig
Ergebnis vom Bearbeiter abhängig
basierend auf wissensbasierten bzw. regelbasierten Ansätzen
Durch ein umfangreiches Regelwerk wird versucht, die Metadaten (insbesondere Art des Dokuments, Vorgangsnummer, Empfänger) automatisch zu ermitteln; um eine automatische Klassifikation und Verarbeitung zu ermöglichen.
basierend auf (überwachten) maschinellen Lernverfahren
Das System wird in einem ersten Schritt - basierend auf eingescannten Dokumenten - überwacht trainiert und kann dann in einem zweiten Schritt die Metadaten automatisch ermitteln.
Strukturierte Suche
Unter Nutzung der Metadaten werden gezielte Anfragen an das DMS gestellt.
Suche per Daten über Dokumente, die nicht unbedingt direkt in den Dokumenten zu finden sind.
Suchraster ist vorgegeben (d. h. Metadatenschema ist fest).
Volltextsuche
Wenn die Dokumente als CI-Dateien vorliegen, dann kann man auch mittels Volltext suchen. Evtl. ergänzt um semantische Hilfsmittel (Thesaurus, etc. ).
Man kann jedes Wort wiederfinden.
Unstrukturiert, „langsam“, Ressourcenbedarf, keine semantisch zusammenfassenden Informationen abfragbar.